mysql查询语句
前言
在线练习网站:sqlzoo
多段代码需要在每句末加;单个不需要
运行原理:where-group by-having-order by-limit-select
select & from
1 | select * from world #查询所有 |
where
1 | where 表达式 #限定查询行必须满足的条件,字符串加'' |
order by (排序)
1 | order by 字段名 asc|desc (升序|降序)#默认升序 |
limit
1 | limit [位置偏移量,]行数 #限制查询结果集合显示的行数 |
聚合函数&group by
1 | 一些函数:sum(),avg(),max(),min() #必须指定字段;不能用通配符;会忽略空值行 |
聚合函数是 SQL 中用于对一组值进行计算并返回单个值的函数。通常与 GROUP BY 子句一起使用,以对结果集进行分组并生成汇总信息。以下是一些常见的聚合函数及其用法说明:
常见聚合函数
COUNT()- 用于计算行数或非空值的数量。
- 语法:
1
SELECT COUNT(column_name) FROM table_name;
- 示例:
1
SELECT COUNT(*) FROM employees; -- 计算员工总数
SUM()- 用于计算数值列的总和。
- 语法:
1
SELECT SUM(column_name) FROM table_name;
- 示例:
1
SELECT SUM(salary) FROM employees; -- 计算所有员工的工资总和
AVG()- 用于计算数值列的平均值。
- 语法:
1
SELECT AVG(column_name) FROM table_name;
- 示例:
1
SELECT AVG(salary) FROM employees; -- 计算员工工资的平均值
MIN()- 用于获取某列的最小值。
- 语法:
1
SELECT MIN(column_name) FROM table_name;
- 示例:
1
SELECT MIN(salary) FROM employees; -- 获取最低工资
MAX()- 用于获取某列的最大值。
- 语法:
1
SELECT MAX(column_name) FROM table_name;
- 示例:
1
SELECT MAX(salary) FROM employees; -- 获取最高工资
GROUP_CONCAT()(MySQL 特有)- 用于将组内的值连接成一个字符串。
- 语法:
1
SELECT GROUP_CONCAT(column_name) FROM table_name GROUP BY another_column;
- 示例:
1
SELECT department, GROUP_CONCAT(employee_name) FROM employees GROUP BY department; -- 按部门列出员工姓名
ARRAY_AGG()(PostgreSQL 特有)- 将组内的值聚合为数组。
- 语法:
1
SELECT ARRAY_AGG(column_name) FROM table_name GROUP BY another_column;
- 示例:
1
SELECT department, ARRAY_AGG(employee_name) FROM employees GROUP BY department; -- 按部门列出员工姓名数组
STRING_AGG()(PostgreSQL 特有)- 将组内的值连接为字符串,可以指定分隔符。
- 语法:
1
SELECT STRING_AGG(column_name, ', ') FROM table_name GROUP BY another_column;
- 示例:
1
SELECT department, STRING_AGG(employee_name, ', ') FROM employees GROUP BY department; -- 按部门列出员工姓名,使用逗号分隔
使用聚合函数的示例
假设我们有一个 sales 表,结构如下:
| id | salesperson | amount | sale_date |
|---|---|---|---|
| 1 | Alice | 100 | 2022-01-01 |
| 2 | Bob | 200 | 2022-01-02 |
| 3 | Alice | 150 | 2022-01-03 |
| 4 | Bob | 300 | 2022-01-04 |
| 5 | Charlie | 250 | 2022-01-05 |
示例查询
计算每个销售人员的总销售额:
1
2
3SELECT salesperson, SUM(amount) AS total_sales
FROM sales
GROUP BY salesperson;计算销售额的平均值:
1
2SELECT AVG(amount) AS average_sales
FROM sales;获取最大和最小销售额:
1
2SELECT MAX(amount) AS max_sale, MIN(amount) AS min_sale
FROM sales;计算每个销售人员的销售次数:
1
2
3SELECT salesperson, COUNT(*) AS sales_count
FROM sales
GROUP BY salesperson;
having
在 SQL 中,HAVING 子句用于对 GROUP BY 生成的结果进行筛选。与 WHERE 子句不同(分组聚合前筛选),HAVING 是在聚合操作之后进行的筛选,因此可以使用聚合函数的结果
以下是 HAVING 子句的一些示例,展示如何在聚合查询中进行筛选。
示例数据
假设我们有一个 sales 表,结构如下:
| id | salesperson | amount | sale_date |
|---|---|---|---|
| 1 | Alice | 100 | 2022-01-01 |
| 2 | Bob | 200 | 2022-01-02 |
| 3 | Alice | 150 | 2022-01-03 |
| 4 | Bob | 300 | 2022-01-04 |
| 5 | Charlie | 250 | 2022-01-05 |
示例查询
筛选总销售额大于 300 的销售人员:
1
2
3
4SELECT salesperson, SUM(amount) AS total_sales
FROM sales
GROUP BY salesperson
HAVING SUM(amount) > 300;- 解释:该查询计算每个销售人员的总销售额,并筛选出总销售额大于 300 的销售人员。
筛选销售次数大于 1 的销售人员:
1
2
3
4SELECT salesperson, COUNT(*) AS sales_count
FROM sales
GROUP BY salesperson
HAVING COUNT(*) > 1;- 解释:该查询计算每个销售人员的销售次数,并筛选出销售次数大于 1 的销售人员。
筛选平均销售额大于 150 的销售人员:
1
2
3
4SELECT salesperson, AVG(amount) AS average_sales
FROM sales
GROUP BY salesperson
HAVING AVG(amount) > 150;- 解释:该查询计算每个销售人员的平均销售额,并筛选出平均销售额大于 150 的销售人员。
筛选销售额总和大于 200 且销售次数大于 1 的销售人员:
1
2
3
4SELECT salesperson, SUM(amount) AS total_sales, COUNT(*) AS sales_count
FROM sales
GROUP BY salesperson
HAVING SUM(amount) > 200 AND COUNT(*) > 1;- 解释:该查询计算每个销售人员的总销售额和销售次数,并筛选出总销售额大于 200 且销售次数大于 1 的销售人员。
筛选总销售额等于 400 的销售人员:
1
2
3
4SELECT salesperson, SUM(amount) AS total_sales
FROM sales
GROUP BY salesperson
HAVING SUM(amount) = 400;- 解释:该查询计算每个销售人员的总销售额,并筛选出总销售额等于 400 的销售人员。
NULL
IS NULL
1 | select name from teacher |
COALESCE 用于返回参数列表中第一个非 NULL 的值
1 | COALESCE(value1, value2, ..., value_n) |
value1, value2, ..., value_n是您希望检查的值。COALESCE将返回第一个非 NULL 的值。如果所有值都是 NULL,则返回 NULL。
1 | # 使用 COALESCE 打印手机号码。如果没有给出号码,则使用号码“07986 444 2266” |
运行原理(总结)
from语句从数据库中调取复制一份表格
where语句在复制的表格中筛选出符合条件的数据行
group by语句依据指定字符对筛选后的数据分区,将依据得到字段去重复,相当于Excel建立了一个数据透视表,添加了行标签
having语句筛选满足条件的分组
order by语句对筛选后的数据排序
limit语句对排序后的数据限制显示的行
select语句,提取最后要显示的字段
部分常见函数
四舍五入函数round(x,y)
1 | ROUND(number, decimals) |
- number:要四舍五入的数字。
- decimals:要保留的小数位数。如果是负数,则表示向左四舍五入。
对x进行四舍五入,精确到小数点后y位 round(3.15,1)=3.2
round(12345, -3)=12000 到千位
取整函数
FLOOR() 函数
FLOOR() 函数用于返回小于或等于指定值的最大整数。为了向下取整到最近的十位,可以将数字除以 10,使用 FLOOR() 进行取整,然后再乘以 10
1 | SELECT FLOOR(39 / 10) * 10 AS rounded_down; |
使用 CEIL() 函数
CEIL() 函数用于返回大于或等于指定值的最小整数。为了向上取整到最近的十位,可以将数字除以 10,使用 CEIL() 进行取整,然后再乘以 10
1 | SELECT CEIL(39 / 10) * 10 AS rounded_up; |
字符串函数
1 | concat(s1,s2,...) 连接字符串,任一参数为null则返回null |
日期时间函数
1 | year(date),month(date),day(date) 获取年月日的函数 |
在 MySQL 中,DATE_FORMAT 函数用于格式化日期和时间。您可以使用多种格式化符号来指定输出格式。以下是 DATE_FORMAT 函数的常用格式符号合集:
DATE_FORMAT
| 格式符号 | 描述 | 示例输出 |
|---|---|---|
%Y |
四位年份 | 2023 |
%y |
两位年份 | 23 |
%m |
两位月份(01-12) | 02 |
%b |
缩写的月份名称 | Feb |
%M |
完整的月份名称 | February |
%d |
两位日期(01-31) | 05 |
%e |
一位或两位日期(1-31) | 5 |
%H |
两位小时(00-23) | 14 |
%h |
两位小时(01-12) | 02 |
%i |
两位分钟(00-59) | 30 |
%s |
两位秒钟(00-59) | 45 |
%p |
AM 或 PM | PM |
%W |
完整的星期名称 | Sunday |
%a |
缩写的星期名称 | Sun |
%d |
一位或两位日期(01-31) | 5 |
%j |
一年中的天数(001-366) | 036 |
%U |
一年中的周数(00-53,周日为一周的第一天) | 05 |
%u |
一年中的周数(00-53,周一为一周的第一天) | 06 |
%V |
ISO 8601 年中的周数 | 2023 |
%v |
ISO 8601 年中的周数(两位) | 23 |
%X |
ISO 8601 年 | 2023 |
%x |
ISO 8601 年(两位) | 23 |
示例用法
以下是一些示例,展示如何使用 DATE_FORMAT 函数:
1 | SELECT DATE_FORMAT(NOW(), '%Y-%m') AS year_month; -- 输出格式为 2023-02 |
TIMESTAMPDIFF 是一个用于计算两个时间戳之间差异的函数,通常用于 MySQL 数据库。与 DATEDIFF 函数不同,TIMESTAMPDIFF 可以返回多种时间单位(如秒、分钟、小时、天、月、年等)的差异。
TIMESTAMPDIFF
1 | TIMESTAMPDIFF(unit, datetime1, datetime2) |
- unit: 指定返回的时间单位,可以是以下之一:
SECOND:秒MINUTE:分钟HOUR:小时DAY:天MONTH:月YEAR:年
- datetime1: 第一个时间戳(较早的时间)。
- datetime2: 第二个时间戳(较晚的时间)。
示例 1:计算小时差
假设我们要计算从 2022-03-22 08:00:00 到 2022-03-22 17:00:00 的时间差,单位为小时:
1 | SELECT TIMESTAMPDIFF(HOUR, '2022-03-22 08:00:00', '2022-03-22 17:00:00') AS hours_difference; |
结果:
1 | +------------------+ |
示例 2:计算天数差
如果我们想要计算两个日期之间的天数差:
1 | SELECT TIMESTAMPDIFF(DAY, '2022-03-20 00:00:00', '2022-03-22 00:00:00') AS days_difference; |
结果:
1 | +------------------+ |
示例 3:计算分钟差
计算两个时间戳之间的分钟差:
1 | SELECT TIMESTAMPDIFF(MINUTE, '2022-03-22 08:00:00', '2022-03-22 09:30:00') AS minutes_difference; |
结果:
1 | +--------------------+ |
注意事项
- 时间单位: 选择合适的时间单位来获取所需的差异。
- 时间格式: 确保输入的时间戳格式正确,通常为
'YYYY-MM-DD HH:MM:SS'。 - 负值: 如果
datetime1晚于datetime2,TIMESTAMPDIFF将返回负值。
条件判断函数
1 | if(expr,v1,v2) |
窗口函数
窗口函数合集
窗口函数(Window Functions)是 SQL 中用于执行计算的函数,在数据集的特定“窗口”上进行操作。窗口函数通常用于分析数据,计算累计值、排名、平均值等,而不需要使用 GROUP BY。以下是一些常见的窗口函数及其用途:
聚合窗口函数
这些函数在指定的窗口内对数据进行聚合计算。
SUM():计算窗口内所有行的总和。1
SUM(column_name) OVER (PARTITION BY column_name ORDER BY another_column)
AVG():计算窗口内所有行的平均值。1
AVG(column_name) OVER (PARTITION BY column_name ORDER BY another_column)
COUNT():计算窗口内的行数。1
COUNT(column_name) OVER (PARTITION BY column_name)
MIN():计算窗口内的最小值。1
MIN(column_name) OVER (PARTITION BY column_name)
MAX():计算窗口内的最大值。1
MAX(column_name) OVER (PARTITION BY column_name)
排名窗口函数
这些函数用于在分组内为每行分配排名。
ROW_NUMBER():为每行分配唯一的序号(在分组内)。1
ROW_NUMBER() OVER (PARTITION BY column_name ORDER BY another_column)
RANK():为每行分配排名,若有相同值,则排名相同。1
RANK() OVER (PARTITION BY column_name ORDER BY another_column)
DENSE_RANK():类似于RANK(),但排名不留空。1
DENSE_RANK() OVER (PARTITION BY column_name ORDER BY another_column)
滚动窗口函数
这些函数用于计算在指定范围内的值。
LEAD():访问当前行之后的某一行的值。1
LEAD(column_name, offset) OVER (ORDER BY another_column)
LAG():访问当前行之前的某一行的值。1
LAG(column_name, offset) OVER (ORDER BY another_column)
FIRST_VALUE():获取窗口内的第一行值。1
FIRST_VALUE(column_name) OVER (PARTITION BY column_name ORDER BY another_column)
LAST_VALUE():获取窗口内的最后一行值。1
LAST_VALUE(column_name) OVER (PARTITION BY column_name ORDER BY another_column ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
窗口帧
窗口函数可以与窗口帧(Window Frame)结合使用,以限制计算的行数。窗口帧定义了在计算时考虑的行的范围。
ROWS BETWEEN:定义一个特定的行数范围。1
SUM(column_name) OVER (ORDER BY another_column ROWS BETWEEN 1 PRECEDING AND CURRENT ROW)
RANGE BETWEEN:定义一个值范围。1
SUM(column_name) OVER (ORDER BY another_column RANGE BETWEEN INTERVAL '1' DAY PRECEDING AND CURRENT ROW)
示例
1. 排名和排序场景
示例:为每个部门的员工按薪水排名
1 | SELECT |
2. 累计计算场景
示例:计算每个员工的累计薪水和移动平均
1 | SELECT |
3. 前后值比较场景
示例:比较当前销售额与上月销售额
1 | SELECT |
4. 百分比和比例计算场景
示例:计算每个产品在总销售额中的占比
1 | SELECT |
5. 分组内极值查找场景
示例:查找每个部门最高薪水的员工
1 | SELECT |
6. 复杂业务分析场景
示例:分析销售趋势(N天移动平均)
1 | SELECT |
7. 分页查询场景
示例:实现高效分页
1 | WITH numbered_rows AS ( |
8. 数据对比分析场景
示例:比较员工薪水与部门平均薪水
1 | SELECT |
partition by
PARTITION BY 是 SQL 中用于窗口函数(Window Functions)的一个子句,允许您在查询结果中对数据进行分组,以便在每个分组内进行计算。使用 PARTITION BY 可以实现许多复杂的分析任务,例如计算每个组的总和、平均值、排名等,而不需要使用传统的 GROUP BY。
基本语法:
1 | SQLSELECT |
window_function()是您想要使用的窗口函数,例如SUM()、AVG()、ROW_NUMBER()等。PARTITION BY column_to_partition指定了您希望如何将数据分组。ORDER BY column_to_order是可选的,用于在每个分组内对数据进行排序。
1.窗口函数写在select后面;2.partition by只分区不去重,不分区则整个表一个区;3.order by是可选项,在分区内排序。
group by和partition by区别
GROUP BY 和 PARTITION BY 是 SQL 中用于处理数据分组的两个不同概念。尽管都涉及到对数据进行分组,但用途和工作方式有显著的区别。以下是主要区别:
用途
GROUP BY:- 用于将结果集中的行按一个或多个列进行分组,并对每个组应用聚合函数(如
SUM()、COUNT()、AVG()等)。 GROUP BY通常与聚合函数一起使用,以生成汇总数据。- 结果集的行数通常会减少,因为每个组只返回一行。
- 用于将结果集中的行按一个或多个列进行分组,并对每个组应用聚合函数(如
PARTITION BY:- 用于在窗口函数(如
ROW_NUMBER()、RANK()、SUM()等)中定义一个数据的分区。 PARTITION BY不会减少结果集的行数,而是允许在每个分区内进行计算,结果集中的每一行都可以保留。- 结果集中每个分区的行都可以访问同一个分区内的其他行。
- 用于在窗口函数(如
语法
GROUP BY:- 语法示例:
1
2
3SELECT column1, SUM(column2)
FROM table_name
GROUP BY column1;
- 语法示例:
PARTITION BY:- 语法示例:
1
2
3SELECT column1, column2,
SUM(column2) OVER (PARTITION BY column1 ORDER BY column3) AS cumulative_sum
FROM table_name;
- 语法示例:
结果集的变化
GROUP BY:- 返回的结果集只包含分组列和聚合结果,通常行数减少。
示例:
1
2
3SELECT department, COUNT(*) AS employee_count
FROM employees
GROUP BY department;假设
employees表中有 100 行数据,按department分组后,结果可能只返回 5 行(每个部门一行)。PARTITION BY:- 返回的结果集包含所有原始列,并为每一行计算聚合值,行数不变。
示例:
1
2
3SELECT employee_id, department,
SUM(salary) OVER (PARTITION BY department ORDER BY employee_id) AS cumulative_salary
FROM employees;这里,结果集仍然会有 100 行,但每行都会显示该部门的累计工资。
使用场景
GROUP BY:- 适用于需要汇总数据的场景,比如计算每个部门的员工数量、每个产品的销售总额等。
PARTITION BY:- 适用于需要在结果集内进行复杂分析的场景,比如计算每个部门的累计工资、每个销售人员的销售排名等。
偏移分析函数
lag/lead(字段名,偏移量[,默认值])over(partition by 字段名 order by 字段名 asc|desc) #lag向上取,lead向下取
通常用于做减法得出增长值,如计算每周一新增xxx
常见的偏移分析函数
LEAD()LEAD()函数用于访问当前行之后的某一行的值。- 语法:
1
LEAD(column_name, offset, default_value) OVER (PARTITION BY partition_column ORDER BY order_column)
offset是可选参数,指定要跳过的行数(默认是 1),default_value是可选的默认值,如果没有找到对应的行则返回该值。
LAG()LAG()函数用于访问当前行之前的某一行的值。- 语法:
1
LAG(column_name, offset, default_value) OVER (PARTITION BY partition_column ORDER BY order_column)
- 与
LEAD()类似,offset和default_value参数的含义相同。
示例
假设我们有一个 sales 表,结构如下:
| id | salesperson | amount | sale_date |
|---|---|---|---|
| 1 | Alice | 100 | 2022-01-01 |
| 2 | Bob | 200 | 2022-01-02 |
| 3 | Alice | 150 | 2022-01-03 |
| 4 | Bob | 300 | 2022-01-04 |
| 5 | Charlie | 250 | 2022-01-05 |
示例 1:使用 LEAD() 函数
计算每位销售人员当前销售额和下一次销售额的差额:
1 | SELECT |
结果:
| salesperson | sale_date | amount | next_amount | amount_difference |
|---|---|---|---|---|
| Alice | 2022-01-01 | 100 | 150 | 50 |
| Alice | 2022-01-03 | 150 | NULL | NULL |
| Bob | 2022-01-02 | 200 | 300 | 100 |
| Bob | 2022-01-04 | 300 | NULL | NULL |
| Charlie | 2022-01-05 | 250 | NULL | NULL |
示例 2:使用 LAG() 函数
计算每位销售人员当前销售额和上一次销售额的差额:
1 | SELECT |
结果:
| salesperson | sale_date | amount | previous_amount | amount_difference |
|---|---|---|---|---|
| Alice | 2022-01-01 | 100 | NULL | NULL |
| Alice | 2022-01-03 | 150 | 100 | 50 |
| Bob | 2022-01-02 | 200 | NULL | NULL |
| Bob | 2022-01-04 | 300 | 200 | 100 |
| Charlie | 2022-01-05 | 250 | NULL | NULL |
使用场景
- 时间序列分析:比较时间序列数据中的当前值与前后值。
- 趋势分析:计算销售趋势、价格变化等。
- 数据完整性检查:检测数据中的异常值或变化。
表连接
基本用法
内/左/右连接
select 字段名
from 表名1 inner/left/right join 表名2 on 表名1.字段名=表名2.字段名 #内连接inner可以忽略(默认)
假设我们有两个表:
- game 表:
| id | game_name |
|---|---|
| 1 | Game A |
| 2 | Game B |
| 3 | Game C |
- goal 表:
| matchid | player_name | goals |
|---|---|---|
| 1 | Player 1 | 2 |
| 1 | Player 2 | 1 |
| 2 | Player 3 | 3 |
| 2 | Player 4 | 4 |
| 2 | Player 5 | 2 |
如果你执行以下查询:
1 | SELECT |
game 表中的 id 列与 goal 表中的 matchid 列进行连接。由于 goal 表中可能有多个行的 matchid 等于 game 表中的 id,结果将如下:
| id | game_name | player_name | goals |
|---|---|---|---|
| 1 | Game A | Player 1 | 2 |
| 1 | Game A | Player 2 | 1 |
| 2 | Game B | Player 3 | 3 |
| 2 | Game B | Player 4 | 4 |
| 2 | Game B | Player 5 | 2 |
1 | select team1, team2, player from game join goal on game.id=goal.matchid where player like 'Mario%' #根据id连接表 |
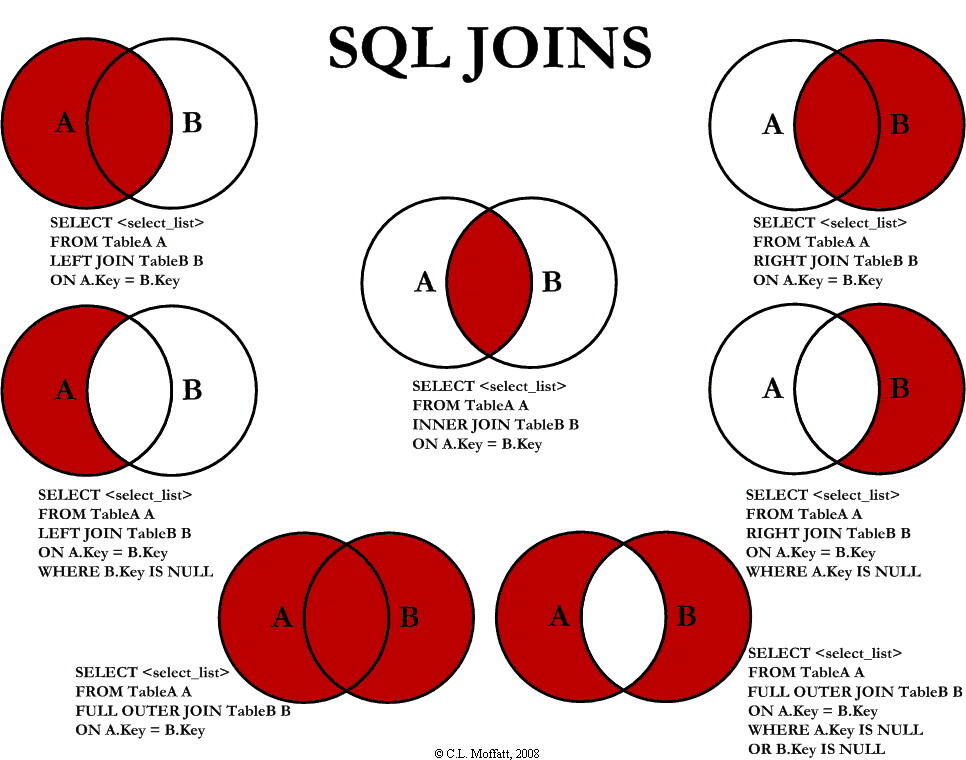
多表连接
假设我们有以下三个表:
- game 表:
| matchid | mdate | team1 | team2 |
|---|---|---|---|
| 1 | 2022-01-01 | A | B |
| 2 | 2022-01-02 | C | D |
- goal 表:
| matchid | teamid | score |
|---|---|---|
| 1 | A | 2 |
| 1 | B | 1 |
| 2 | C | 3 |
| 2 | D | 0 |
- player 表:
| playerid | name | teamid |
|---|---|---|
| 1 | Player 1 | A |
| 2 | Player 2 | B |
| 3 | Player 3 | C |
| 4 | Player 4 | D |
我们希望查询每场比赛的日期、球队、得分和球员。可以使用以下 SQL 查询:
1 | SELECT |
选择字段:选择比赛日期、球队、得分和参与的球员。
连接表
- 使用
LEFT JOIN将goal表连接到game表,以获取每场比赛的得分。 - 使用
LEFT JOIN将player表连接到goal表,以获取得分球队的球员。
- 使用
聚合函数
- 使用
SUM来计算每个球队的总得分。 - 使用
GROUP_CONCAT来列出每个球队的所有球员名字。
- 使用
分组和排序:根据比赛 ID 和日期进行分组,并按日期排序。
子查询
1.子查询本身就是一个完整的查询,用括号包裹在主查询中;
2.子查询的结果返回给主查询;
3.子查询可以在select, from, where, having子句中使用,但注意不同句子能接受的子查询种类有差别;
4.子查询可以多重嵌套
1 | select name from world where gdp is not null and |
可以用ALL 对一个列表进行>=或>或<或<=充当比较
1 | # 哪些国家的gdp比欧洲所有国家都高 |
为表格再命名,便可以分出不同的表格
1 | # 在每一个洲中找出面积最大的国家 |
SQL语句的格式规范
SQL 语句的代码格式通常遵循一定的规范,以提高可读性和维护性。以下是一些常见的 SQL 语句格式规范和最佳实践:
1. 关键字大写
SQL 语句中的关键字(如 SELECT、FROM、WHERE、JOIN、INSERT、UPDATE、DELETE 等)通常使用大写字母,以便于快速识别。
2. 每个子句独占一行
将每个主要子句(如 SELECT、FROM、WHERE 等)放在单独的一行上,有助于提高可读性。
3. 缩进
对于嵌套的查询或多行的条件,使用适当的缩进来表示层次关系。
4. 逗号后换行
在 SELECT 和 INSERT 语句中,每个列名后面的逗号后换行,以便于添加或删除列时更容易进行修改。
5. 使用空格分隔
在 SQL 语句中,适当使用空格以提高可读性,特别是在关键字、列名和运算符之间。
6. 适当使用注释
在复杂的查询中,使用注释(-- 或 /* ... */)来解释查询的目的或特定部分的功能。
示例 SQL 语句格式
以下是一个遵循上述格式规范的 SQL 查询示例:
1 | SELECT |
常见查询
连续登录
找出连续登录至少3天的用户
register_tb (用户注册表)
| user_id | register_date |
|---|---|
| 1 | 2023-01-01 |
| 2 | 2023-01-01 |
| 3 | 2023-01-01 |
login_tb (用户登录表)
| user_id | login_date |
|---|---|
| 1 | 2023-01-01 10:00 |
| 1 | 2023-01-02 09:30 |
| 1 | 2023-01-03 14:20 |
| 1 | 2023-01-05 11:15 |
| 2 | 2023-01-01 08:00 |
| 2 | 2023-01-02 16:45 |
| 2 | 2023-01-03 10:30 |
| 3 | 2023-01-01 12:00 |
| 3 | 2023-01-03 09:00 |
| 3 | 2023-01-04 15:20 |
1 | with demo as |
表达式 DATE(login_date) - INTERVAL ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY login_date) DAY AS date_group 的目的是为了创建一个可以帮助识别连续登录的分组标识。下面是对这个表达式的详细解释:
1. ROW_NUMBER() 函数
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY login_date)是一个窗口函数,为每个user_id的登录记录生成一个唯一的序列号,按login_date排序。- 例如,对于某个用户的登录记录,如果该用户有 5 次登录,按日期排序后,
ROW_NUMBER()将为这些登录记录分配 1 到 5 的序号。
2. DATE(login_date)
DATE(login_date)将login_date转换为日期格式(去掉时间部分),确保我们只关注日期部分。
3. INTERVAL 关键字
INTERVAL ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY login_date) DAY表示将ROW_NUMBER()生成的序列号作为天数进行减法操作。- 例如,如果某个用户在 2022-03-20、2022-03-21 和 2022-03-22 登录,
ROW_NUMBER()将为这些登录记录生成序号 1、2 和 3。
4. 计算过程
对于 user_id = 1:
| user_id | login_date | ROW_NUMBER | 计算过程 | date_group |
|---|---|---|---|---|
| 1 | 2023-01-01 | 1 | 2023-01-01 - 1 day = 2022-12-31 | 2022-12-31 |
| 1 | 2023-01-02 | 2 | 2023-01-02 - 2 day = 2022-12-31 | 2022-12-31 |
| 1 | 2023-01-03 | 3 | 2023-01-03 - 3 day = 2022-12-31 | 2022-12-31 |
| 1 | 2023-01-05 | 4 | 2023-01-05 - 4 day = 2023-01-01 | 2023-01-01 |
结果:user_id=1 有连续3天登录(1-1到1-3)
对于 user_id = 2:
| user_id | login_date | ROW_NUMBER | date_group |
|---|---|---|---|
| 2 | 2023-01-01 | 1 | 2022-12-31 |
| 2 | 2023-01-02 | 2 | 2022-12-31 |
| 2 | 2023-01-03 | 3 | 2022-12-31 |
结果:user_id=2 有连续3天登录
对于 user_id = 3:
| user_id | login_date | ROW_NUMBER | date_group |
|---|---|---|---|
| 3 | 2023-01-01 | 1 | 2022-12-31 |
| 3 | 2023-01-03 | 2 | 2023-01-01 |
| 3 | 2023-01-04 | 3 | 2023-01-01 |
结果:user_id=3 没有连续3天登录(1-3和1-4是连续的,但缺少1-2)
最终结果
| user_id |
|---|
| 1 |
| 2 |
这个查询巧妙地利用了日期运算和行号的组合来识别连续日期,是一种常见的处理连续性问题的方法。
5. 分组标识的作用
- 通过这种计算,所有连续登录的日期会得到相同的
date_group值。上面的例子中,所有的登录记录都会被标识为2022-03-19。 - 这意味着,如果一个用户在连续的几天内登录,所有这些登录记录的
date_group值将相同,从而可以通过GROUP BY进行分组,计算连续登录的天数。
6. 总结
这个计算的核心思想是通过将登录日期减去其在该用户的登录序列中的位置(天数),来生成一个统一的分组标识,从而使得连续的登录日期能够被归为同一组。这样,后续的 GROUP BY 操作就可以轻松地统计出每个用户的连续登录天数。